For this part, we’re going to automate pulls of our project to the Linux Server we did set up in Part II.
Make sure you have a GitHub account before start.
Adding 2 factor authentication to GitHub and SSH keys
- Sign into GitHub and go to Settings
- Select Security from left menu
- Click on Enable two-factor authentication and follow the instructions
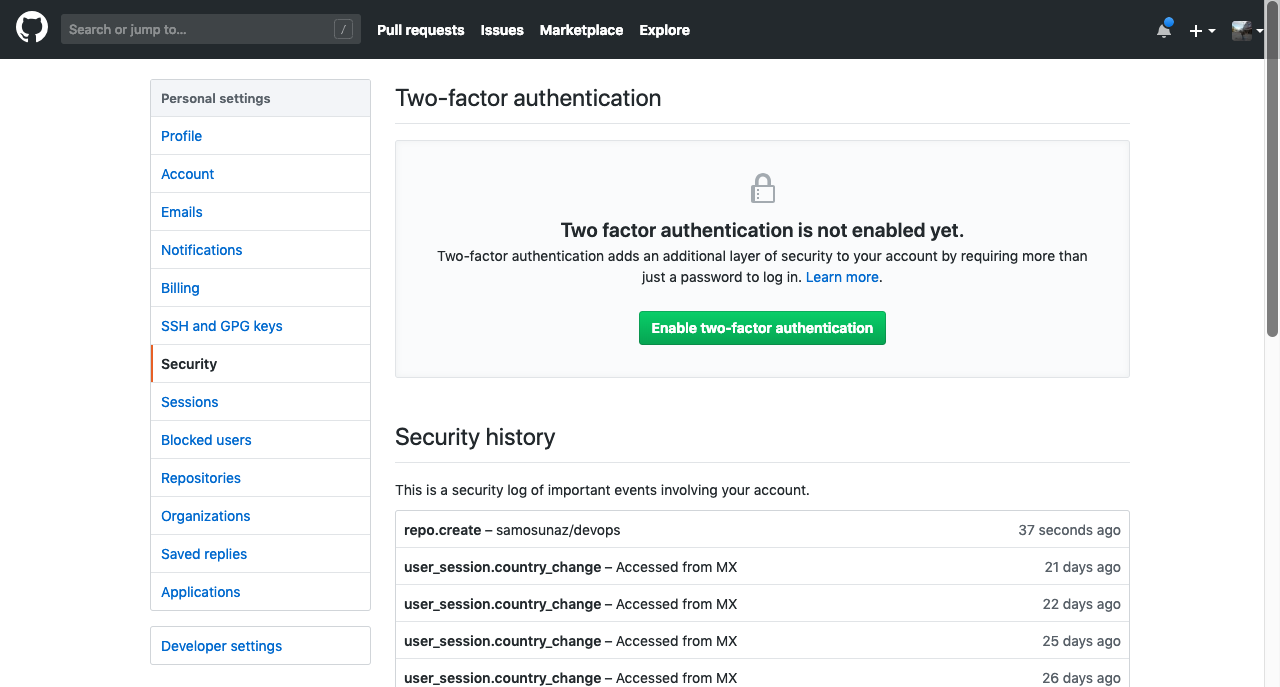
- Choose the desired method, I did it with SMS
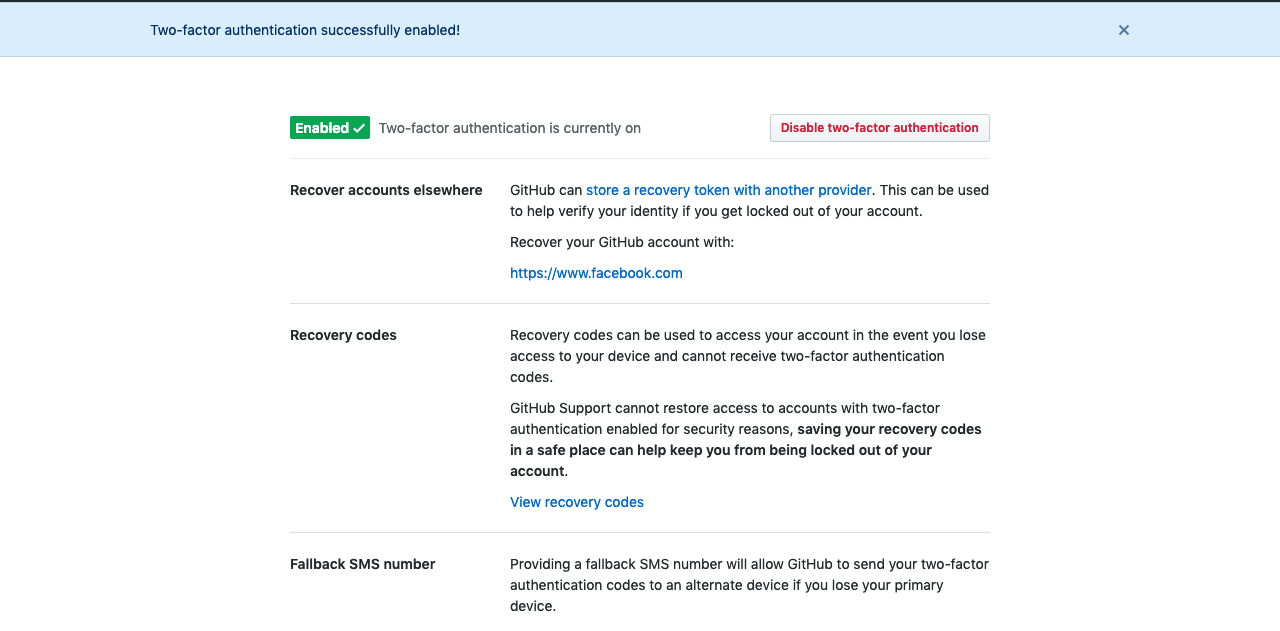
- Once you finish, you’ll see a page like this
To add SSH keys do the following:
- Sign into GitHub and go to Settings
- Choose SSH and GPG Keys in the left menu
- Click on the New SSH button
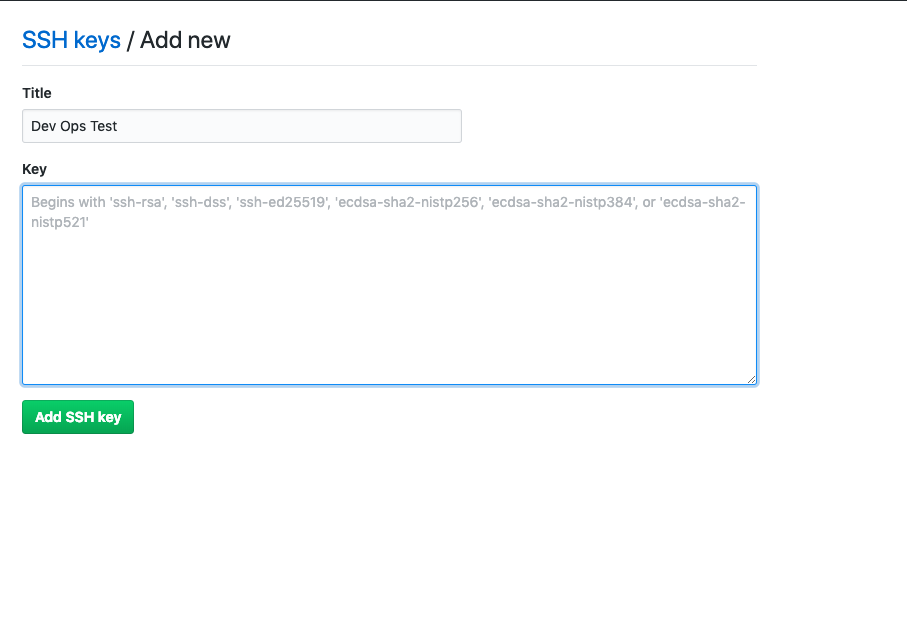
- Set the title to this new SSH and to generate it we will do the following:
Inside the Virtual Machine, open the terminal app and run the following command
ssh-keygen -t rsa
Follow the prompted instructions to store it in your machine. Once the key is generated, try to clone the repo we previously created in Part II using the SSH method. If it clones without any problem, it means that it worked!
Make any change to the repo and commit it. Try to pull from the VM to ensure it works.
We’re going to automate pulls from our project to keep the website updated. Let’s create a simple shell script.
mkdir cicd_scripts
cd cicd_scripts
touch automate_pull.sh
vim automate_pull.sh
/** automate.pull.sh **/
cd $HOME/Server/devops // This is the path to my project
git pull origin master
/** automate.pull.sh **/
Now, let’s modify our cronjobs
crontab -e
// Add this at the end of the file
* * * * * sh $HOME/cicd_scripts/automate_pull.sh
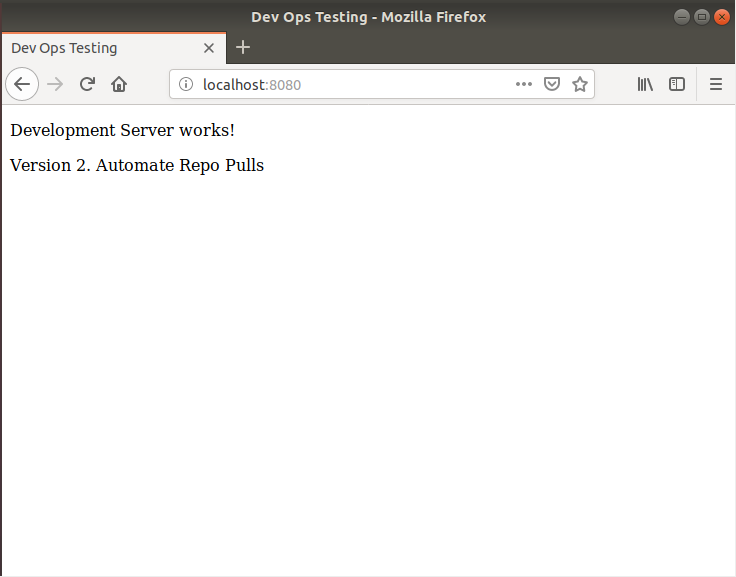
Our server will be doing pulls to the master branch every minute, to keep it updated. Let’s make a small change and commit it.

Open the browser and refresh the page, it has the changes we made! Now you have automated pulls in your server!
How often should we update?
It depends on the project, I’ll go for after midnight, around 2:00 A.M. – 3:00 A.M., to ensure that there is less traffic in the website, unless it is a critical change that has to be updated right now.
How do you ensure (and you should do this) that you do not end up with two copies of your update script running at the same time?
There are tools to accomplish this. One method that I liked is using flock. It came bundled with Ubuntu, basically it is a tool that if a job is running, it creates a lockfile to prevent running more than one instance of a jobs. It is very easy to use it, to add it to our current jobs we just write the following
* * * * * /usr/bin/flock -w 0 $HOME/cicd_scripts/cicd.lockfile sh $HOME/cicd_scripts/automate_pull.sh
We’re telling it to create a lock file inside our scripts folder, it will prevent running our script more than one time
This has to be done for every cron jobs that we create.
Stay tuned for the Part IV post!
References:
https://ma.ttias.be/prevent-cronjobs-from-overlapping-in-linux/
