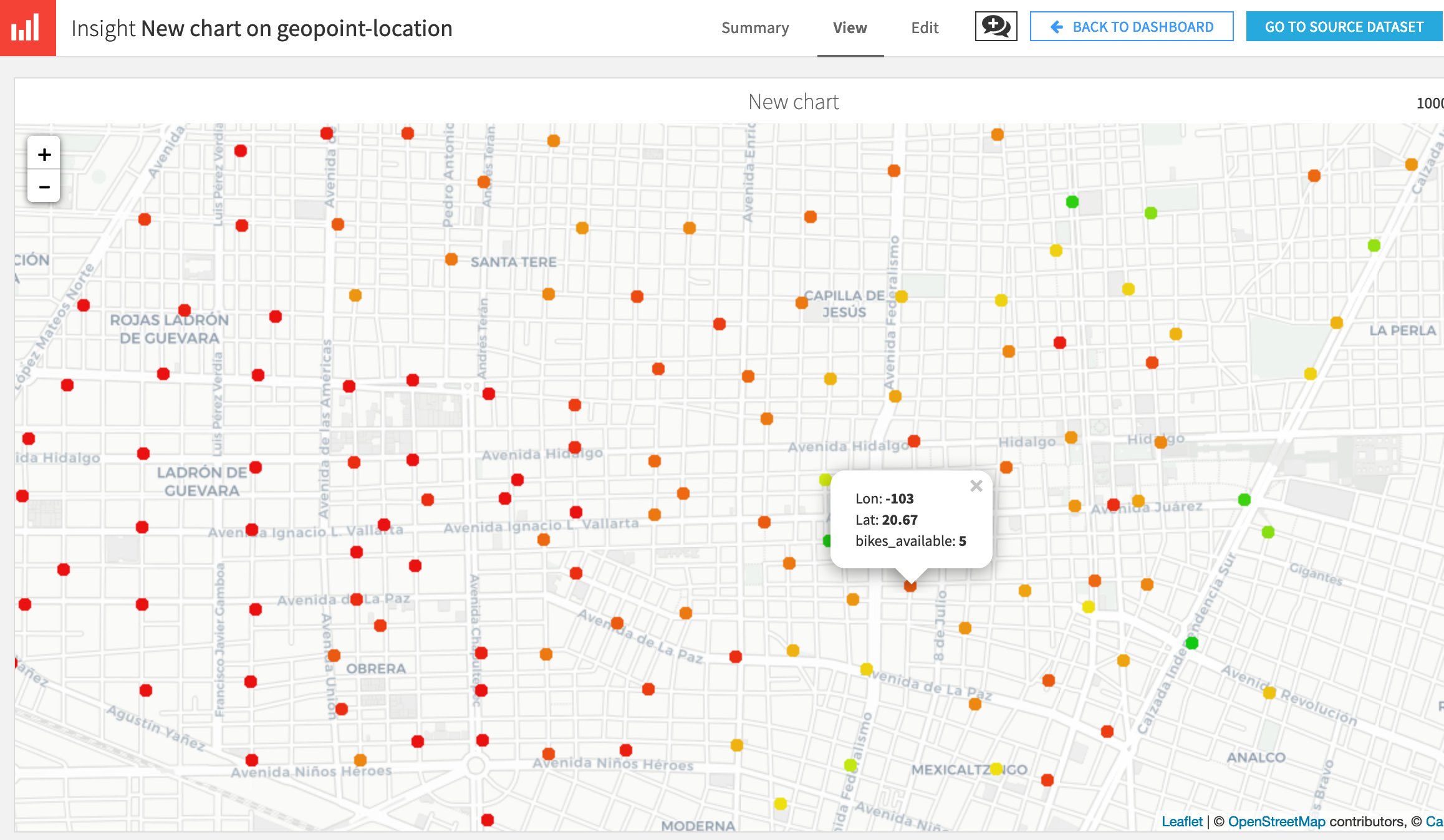
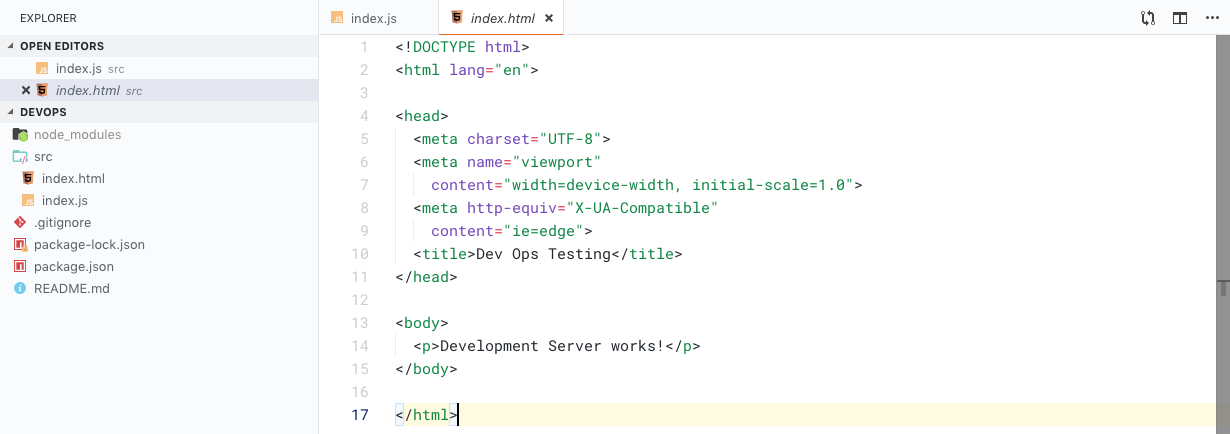
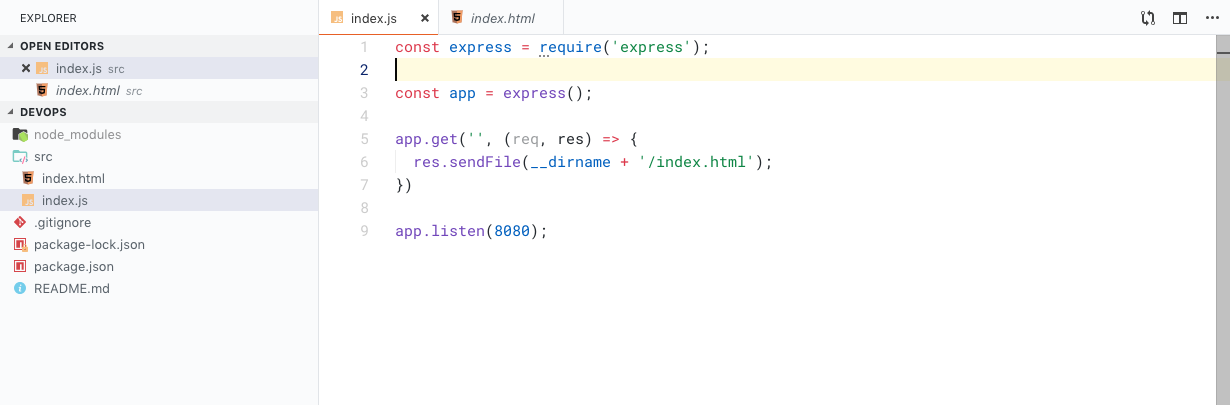
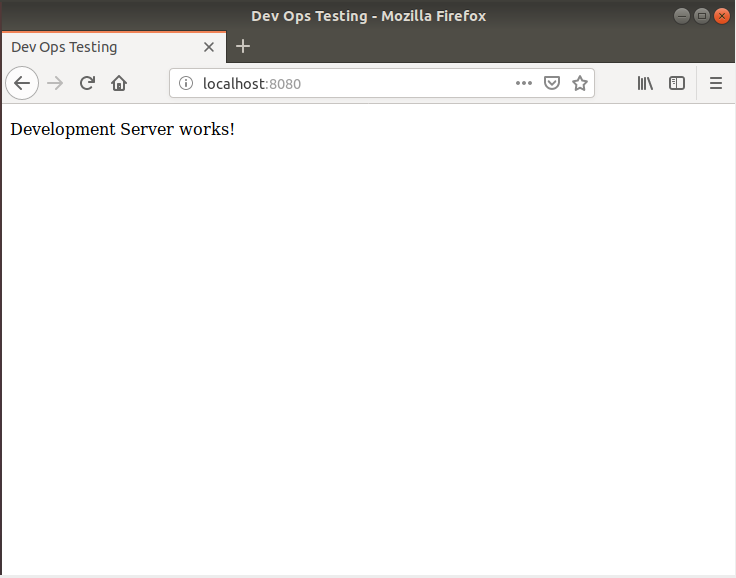
In this blog post I will include my thoughts about the classes TC3045 (Software Quality and Testing) and CB00881 (Smart Citizens)
First of all, these were my first and last classes (because I’m graduating and I’m not planning to do a Masters) using the Flipped Learning method. I found it very interesting because I had a lot of flexibility in terms of homeworks and tasks, at the start of the semester I was working in a full-time job so I have the option to complete all my pending assignments in my free time. To be honest, I should have been more careful about the deadlines and deliveries because I have a considerable amount of accumulated tasks to do at the end of the semester.
About the content of the classes and assignments, they met my expectations, there were some assignments that challenged myself and taught me new things. At the start of the semester, we have to write blogs weekly for CB00881, I wrote a few on time because I don’t have the writing habit developed, I don’t really like writing so much, but I want to. Recently I started to read more blogs about the new technologies, the updates and improvements in the actual ones, and some tutorial blogs to develop something using a language or framework. I want to share some knowledge to the world and start writing some blog stuff and link the code I used to my GitHub repo, I proposed myself that I want to contribute to some Open Source repos in order to thanks all the amazing people that are doing it and all the times I used those repos. I hope I will do it.
Ken is amazing teacher, he really knows how to transmit his knowledge and encourage you to learn. But apart of being a good teacher, he is a great human being, he is always open to talk to you about your thoughts, life, work, feelings and whatever you want, he will listen and he will be there to help.